Computer scientist and computational linguist Benji Smith took down his site Prosecraft last week after authors expressed outrage at its existence. Prosecraft consisted of linguistic analysis of more than 25,000 books by thousands of different authors. The site had been operating since 2017, but most authors had no idea it existed before last week.
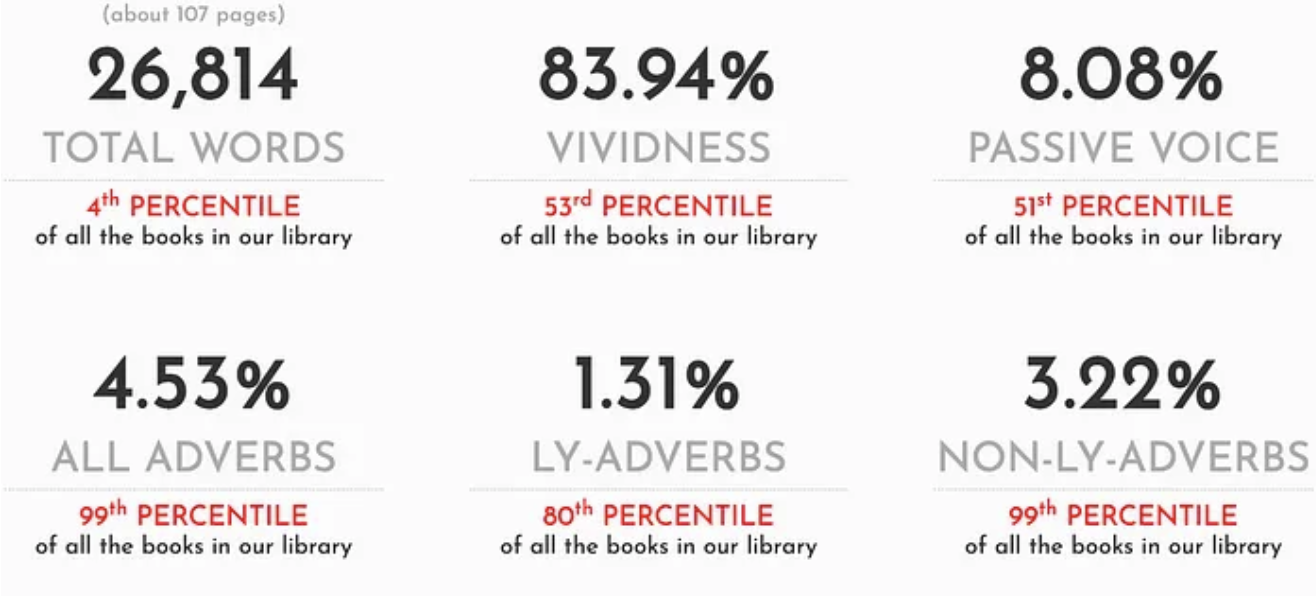
Prosecraft measured length, “vividness,” passive voice, adverb usage, and more. Being able to produce such textual analysis required the full text of literary works, which Smith says he found using a web crawler. Given that Prosecraft included works still under copyright, Smith’s crawler obviously scooped up works from countless pirate libraries that have come and gone over the years.
As soon as Smith realized his efforts were not welcome (an understatement), he took down the site and wrote a post explaining his motivations: He wanted to give “storytellers a suite of ‘lexicographic’ tools that they could use to compare their own writing with the writing of authors they admire.”
Smith did research copyright law and believed that his textual analysis project was protected under fair use—not an unreasonable conclusion for anyone familiar with the Google Books scanning case. Scanning books is not necessarily a copyright violation; it’s how the scans are used. Google scanned millions of books and now, in what is considered fair use under US law, offers brief snippets in response to searches. Under specific conditions, copyright exceptions can be allowed in other countries for text and data mining.
Legal or not, many authors believed Smith could and would ultimately profit off their books in ways they didn’t consent to, and fears surrounding generative AI and language learning models only compounded the concern that his database would be used for ill.
Kate Knibbs at Wired has the most thoughtful coverage of the situation, with insights from experts in copyright and fair use. It concludes, “This incident is illustrative of a larger cultural turn against the unauthorized use of creative work in training models. In this specific case, writers scored an easy victory against one dude in Oregon with a shaky grasp on the concept of passive voice. I suspect the reason so many prominent voices celebrated so loudly is because the larger ongoing fights will be much longer and much harder to win.”

Jane Friedman has spent her entire career working in the publishing industry, with a focus on business reporting and author education. Established in 2015, her newsletter The Bottom Line provides nuanced market intelligence to thousands of authors and industry professionals; in 2023, she was named Publishing Commentator of the Year by Digital Book World.
Jane’s expertise regularly features in major media outlets such as The New York Times, The Atlantic, NPR, The Today Show, Wired, The Guardian, Fox News, and BBC. Her book, The Business of Being a Writer, Second Edition (The University of Chicago Press), is used as a classroom text by many writing and publishing degree programs. She reaches thousands through speaking engagements and workshops at diverse venues worldwide, including NYU’s Advanced Publishing Institute, Frankfurt Book Fair, and numerous MFA programs.